
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Einleitung
Die Bundesliga und der Algorithmus – noch vor zehn Jahren klang diese Verbindung nach einem schlechten Science-Fiction-Film. Heute gehören Supercomputer, die jedes Spiel zehntausende Male simulieren, zum festen Inventar der Fußballanalyse. Sie berechnen Wahrscheinlichkeiten auf zwei Nachkommastellen, prognostizieren Ergebnisse mit einer Präzision, die selbst erfahrene Scouts ins Grübeln bringt, und versprechen nicht weniger als die Entschlüsselung des unberechenbaren Spiels. Doch was steckt wirklich hinter dem Hype um die KI Bundesliga Prognose? Handelt es sich um eine echte Revolution oder nur um alten Wein in neuen Schläuchen?
Wer sich heute mit Fußballvorhersagen beschäftigt, kommt an künstlicher Intelligenz nicht mehr vorbei. Die Schlagzeilen überschlagen sich: „Supercomputer sagt Meister voraus", „KI tippt alle Spieltage", „Algorithmus schlägt Experten". Die Wahrheit ist, wie so oft, komplizierter. Ja, maschinelles Lernen hat die Art und Weise, wie wir Fußball analysieren, grundlegend verändert. Die Möglichkeiten, riesige Datenmengen zu verarbeiten und Muster zu erkennen, die dem menschlichen Auge verborgen bleiben, sind beeindruckend. Gleichzeitig bleibt Fußball ein Spiel voller Emotionen, Überraschungen und jener magischen Momente, die sich jedem Modell entziehen.
Dieser Artikel nimmt dich mit auf eine Reise durch die Welt der datenbasierten Spielvorhersage. Wir schauen uns an, welche Daten in eine moderne KI-Prognose einfließen, wie die verschiedenen Modelle funktionieren und wo ihre Grenzen liegen. Dabei geht es nicht darum, blinden Fortschrittsglauben zu predigen oder Technologie zu verteufeln. Es geht um ein realistisches Verständnis dessen, was KI im Kontext der Bundesliga leisten kann – und was eben nicht. Denn nur wer die Mechanismen versteht, kann die Ergebnisse richtig einordnen und für sich nutzen.
Die zentrale Frage, die uns dabei begleitet: Kann ein Algorithmus wirklich vorhersagen, ob der FC Bayern am Samstag gegen Dortmund gewinnt? Die kurze Antwort lautet: Nein, aber. Nein, weil keine noch so ausgefeilte KI den Ausgang eines einzelnen Spiels mit Sicherheit vorhersagen kann. Aber ja, weil moderne Modelle durchaus in der Lage sind, Wahrscheinlichkeiten zu berechnen, die langfristig erstaunlich präzise sind. Der Unterschied zwischen diesen beiden Aussagen ist fundamental für alles, was folgt.
Diese Unterscheidung zwischen Gewissheit und Wahrscheinlichkeit ist nicht nur akademisch, sondern hat ganz praktische Konsequenzen. Wer eine Prognose als absolute Vorhersage missversteht, wird frustriert sein, wenn sie nicht eintrifft. Wer sie als informierte Einschätzung unter Unsicherheit begreift, kann sie als wertvolles Werkzeug nutzen. In diesem Sinne wollen wir im Folgenden nicht nach dem heiligen Gral der perfekten Vorhersage suchen, sondern verstehen, wie datenbasierte Prognosen funktionieren und wo ihre Stärken und Schwächen liegen.
Was ist eine KI Bundesliga Prognose?
Bevor wir tiefer einsteigen, sollten wir klären, was wir eigentlich meinen, wenn wir von einer KI Bundesliga Prognose sprechen. Im Kern handelt es sich um den Einsatz von Algorithmen des maschinellen Lernens, um den Ausgang von Fußballspielen vorherzusagen. Das klingt zunächst abstrakt, lässt sich aber an einem einfachen Beispiel veranschaulichen: Stell dir vor, du hättest Zugang zu den Daten aller Bundesligaspiele der letzten zwanzig Jahre – Tore, Schüsse, Ballbesitz, Laufwege, Passquoten und hunderte weitere Metriken. Ein Mensch könnte diese Datenmenge niemals vollständig erfassen. Ein Computer schon.
Die Idee, Fußballergebnisse statistisch vorherzusagen, ist dabei alles andere als neu. Schon in den 1990er Jahren experimentierten Mathematiker mit Modellen, die auf der Poisson-Verteilung basierten – einer statistischen Methode, die davon ausgeht, dass Tore in einem Fußballspiel als zufällige Ereignisse mit einer bestimmten erwarteten Häufigkeit auftreten. Diese klassischen Ansätze haben eines gemeinsam: Sie arbeiten mit klar definierten Regeln und Formeln, die ein Mensch nachvollziehen kann. Der Computer rechnet schneller, aber er denkt nicht anders als der Statistiker, der das Modell entworfen hat.

Was moderne KI-Systeme davon unterscheidet, ist ihre Fähigkeit, selbstständig zu lernen. Statt einem starren Regelwerk zu folgen, analysieren Machine-Learning-Algorithmen die Daten und erkennen Zusammenhänge, die kein Mensch explizit programmiert hat. Ein neuronales Netzwerk beispielsweise kann feststellen, dass bestimmte Kombinationen von Faktoren – etwa die Form der letzten fünf Spiele, die Anzahl der Ausfälle im Mittelfeld und die Distanz der Auswärtsreise – einen messbaren Einfluss auf den Spielausgang haben. Diese Muster entstehen aus den Daten selbst, nicht aus menschlichen Annahmen.
Der Begriff „künstliche Intelligenz" ist dabei durchaus mit Vorsicht zu genießen. Was wir in der Praxis sehen, sind keine denkenden Maschinen im Sinne von Science-Fiction, sondern hochspezialisierte statistische Werkzeuge. Sie können keine Fußballspiele verstehen, sie können keine Taktik analysieren, sie können nicht erklären, warum ein Spieler an einem bestimmten Tag über sich hinauswächst. Was sie können, ist das Erkennen von Korrelationen in historischen Daten und das Ableiten von Wahrscheinlichkeiten für zukünftige Ereignisse. Das ist weniger spektakulär, als es klingt, aber trotzdem bemerkenswert nützlich.
In der Praxis begegnen dir KI Bundesliga Prognosen in verschiedenen Formen. Manche Plattformen präsentieren einfache Tipps: Bayern gewinnt, Dortmund verliert, Frankfurt spielt Unentschieden. Seriösere Angebote gehen darüber hinaus und liefern Wahrscheinlichkeitsverteilungen. Sie sagen also nicht „Bayern gewinnt", sondern „Bayern gewinnt mit 65 Prozent Wahrscheinlichkeit, das Unentschieden liegt bei 20 Prozent, Dortmund gewinnt mit 15 Prozent". Der Unterschied mag subtil erscheinen, ist aber entscheidend: Ersteres täuscht Sicherheit vor, die es nicht gibt; Letzteres respektiert die inhärente Unsicherheit des Spiels.
Die Datenbasis: Was fließt in eine KI-Prognose ein?
Die Qualität jeder Prognose steht und fällt mit den Daten, auf denen sie basiert. Das gilt für menschliche Experten genauso wie für Algorithmen. Im Fall der KI ist die Datenbasis allerdings um Größenordnungen umfangreicher, als es ein Mensch jemals überblicken könnte. Moderne Tracking-Systeme erfassen während eines Bundesligaspiels mehrere Millionen Datenpunkte pro Partie. Die Herausforderung besteht nicht darin, genug Daten zu haben, sondern darin, die richtigen auszuwählen und sinnvoll zu verarbeiten.
Die offensichtlichste Datenquelle sind die klassischen Spielstatistiken: Tore, Schüsse, Schüsse aufs Tor, Ballbesitz, Passquote, Fouls, Ecken, Gelbe Karten. Diese Zahlen findest du nach jedem Spieltag in der Sportpresse, und sie bilden das Fundament jeder statistischen Analyse. Schon auf dieser Ebene zeigt sich der Vorteil maschineller Auswertung: Während ein menschlicher Analyst vielleicht die letzten fünf Spiele im Detail anschaut, kann ein Algorithmus die gesamte Saisonhistorie beider Mannschaften einbeziehen, jeden direkten Vergleich der letzten zwanzig Jahre berücksichtigen und Muster über tausende von Spielen hinweg erkennen.
Doch die klassischen Statistiken haben einen gravierenden Nachteil: Sie messen das Ergebnis, nicht den Prozess. Zehn Torschüsse aus 25 Metern Entfernung sind qualitativ etwas völlig anderes als drei Schüsse aus fünf Metern. Genau hier setzen die fortgeschrittenen Metriken an, allen voran die Expected Goals, auf die wir gleich noch ausführlich eingehen werden. Diese Kennzahlen versuchen, die Qualität von Torchancen zu quantifizieren und so ein realistischeres Bild der Spielstärke zu zeichnen, als es reine Torstatistiken können. Ein Team, das regelmäßig mehr hochwertige Chancen kreiert als der Gegner, wird langfristig mehr Spiele gewinnen – auch wenn das in einem einzelnen Match nicht immer so aussieht.
Neben den Spieldaten fließen in viele Modelle auch externe Faktoren ein, die auf den ersten Blick nichts mit Fußball zu tun haben. Die Reisedistanz zum Auswärtsspiel etwa korreliert nachweislich mit der Leistung: Teams, die am Vorabend noch 500 Kilometer im Bus saßen, sind statistisch etwas weniger leistungsfähig als ausgeruhte Mannschaften. Ähnlich verhält es sich mit dem Spielplan: In englischen Wochen, wenn drei Partien innerhalb von sieben Tagen anstehen, sinkt die Punkteausbeute messbar. Auch Wetterbedingungen spielen eine Rolle, insbesondere bei extremer Hitze oder schwerem Regen, die bestimmten Spielstilen mehr entgegenkommen als anderen.
Ein besonders interessanter Datenbereich betrifft die Marktwerte und finanziellen Ressourcen der Vereine. Die Idee dahinter ist simpel: Teurere Spieler sind im Durchschnitt besser, und reichere Vereine können sich bessere Spieler leisten. Tatsächlich zeigen Analysen, dass der Gesamtmarktwert eines Kaders einer der stärksten Einzelprädiktoren für den Saisonerfolg ist. Bayern München wird nicht zufällig jedes Jahr Meister. Das bedeutet nicht, dass Geld immer gewinnt – die Fußballgeschichte ist voll von Überraschungen –, aber es verschiebt die Wahrscheinlichkeiten messbar. Die Korrelation zwischen Kaderwert und Tabellenplatz in der Bundesliga liegt bei über 0,8, was einen außerordentlich starken Zusammenhang darstellt.
Neuere Entwicklungen beziehen auch psychologische und taktische Daten ein, soweit diese quantifizierbar sind. Pressingintensität, Kompaktheit der Defensive, durchschnittliche Ballbesitzposition – all das lässt sich mittlerweile messen und in Prognosemodelle einfließen lassen. Die Herausforderung besteht darin, diese Daten sinnvoll zu gewichten und aus der schieren Masse an Informationen diejenigen herauszufiltern, die tatsächlich prognostische Kraft haben.
Die Herausforderung für jedes Prognosemodell besteht darin, all diese unterschiedlichen Datenquellen sinnvoll zu gewichten. Wie viel zählt die Form der letzten fünf Spiele im Vergleich zur Saisonbilanz? Wie stark sollte ein Verletzungsausfall des Stammtorwarts ins Gewicht fallen? Wie relevant ist die Tatsache, dass eine Mannschaft am Dienstag noch Champions League gespielt hat? Es gibt keine universell richtigen Antworten auf diese Fragen, und verschiedene Modelle setzen hier unterschiedliche Schwerpunkte. Genau das macht den Unterschied zwischen guten und schlechten Prognosen aus.
Expected Goals: Das Fundament moderner Prognosen
In den letzten Jahren hat sich eine Kennzahl zum absoluten Goldstandard der Fußballanalyse entwickelt: Expected Goals, kurz xG. Der Begriff taucht mittlerweile in jeder ernsthaften Spielanalyse auf, und wer sich mit KI-Prognosen beschäftigt, kommt daran nicht vorbei. Dabei ist das Konzept im Grunde verblüffend einfach: Expected Goals messen, wie viele Tore ein Team aufgrund der Qualität seiner Chancen hätte erzielen müssen – unabhängig davon, wie viele tatsächlich gefallen sind.
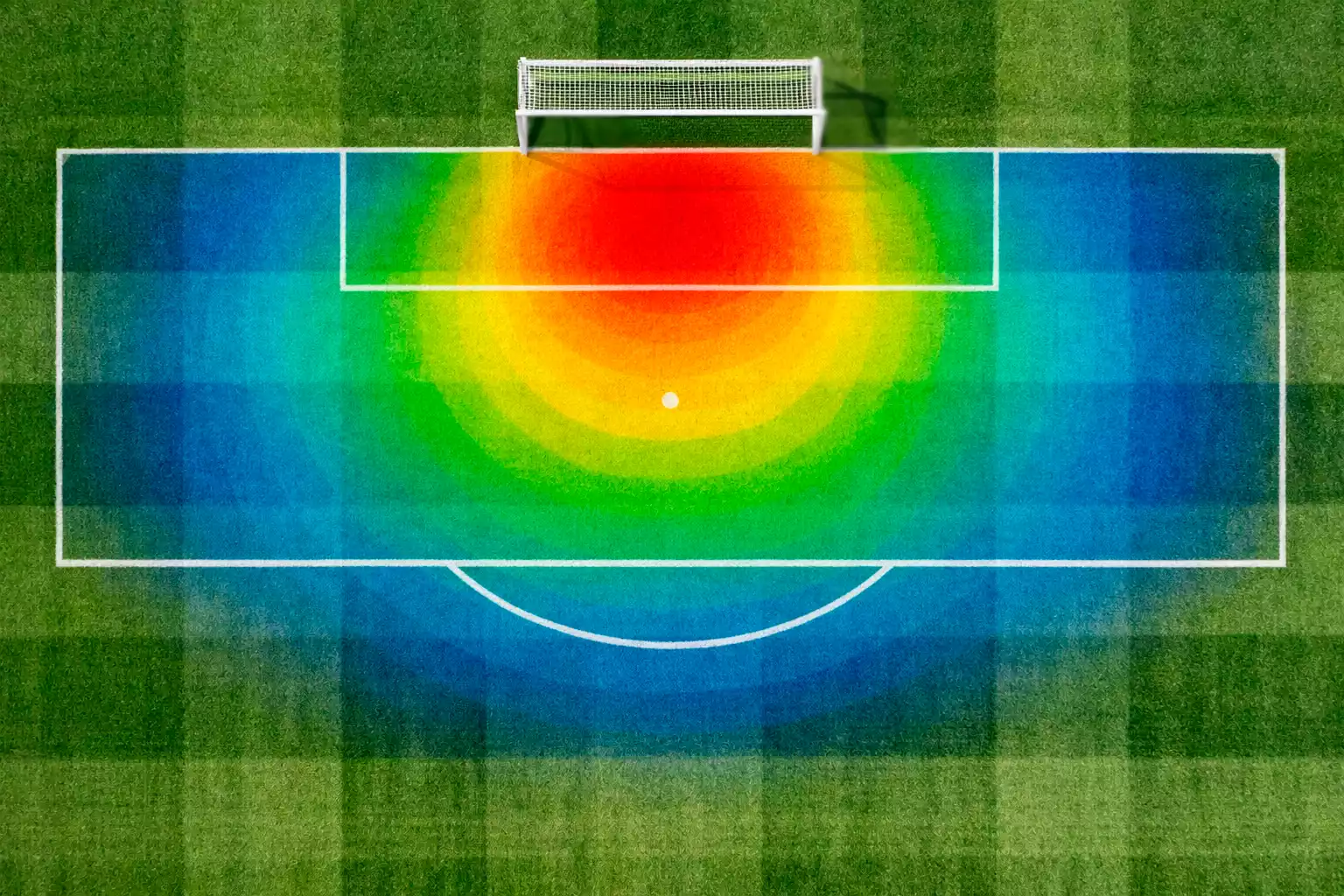
Die Berechnung funktioniert folgendermaßen: Jeder Torschuss wird anhand historischer Daten bewertet. Ein Schuss aus fünf Metern Entfernung, zentral vor dem Tor, ohne Gegenspieler im Weg, führt in etwa 75 Prozent der Fälle zu einem Treffer – er erhält also einen xG-Wert von 0,75. Ein Fernschuss aus 25 Metern, in spitzem Winkel, gegen einen positionierten Torwart, mündet dagegen nur in etwa drei Prozent der Fälle in einem Tor und wird mit 0,03 xG bewertet. Die Summe aller xG-Werte einer Mannschaft ergibt deren Expected Goals für das Spiel. Liegt dieser Wert bei 2,5 und das Team hat nur ein Tor erzielt, spricht man davon, dass es unter seinen Erwartungen geblieben ist.
Der entscheidende Vorteil gegenüber klassischen Torstatistiken liegt in der Prozessorientierung. Ein Team kann ein Spiel mit 1:0 gewinnen und trotzdem die schlechtere Mannschaft gewesen sein, wenn der Gegner Chancen im Wert von 3 xG hatte und nur an einem brillanten Torwart oder Pfosten und Latte scheiterte. Umgekehrt kann ein 0:0 durchaus wertvoll sein, wenn die eigenen xG bei 2,5 lagen und nur das Glück fehlte. Diese Unterscheidung zwischen Prozessqualität und Ergebnis ist fundamental für jede seriöse Spielanalyse.
Für KI-Prognosemodelle sind Expected Goals aus mehreren Gründen unverzichtbar. Erstens liefern sie ein stabileres Signal als reine Torstatistiken. Tore in einem einzelnen Spiel unterliegen erheblichen Zufallsschwankungen – manchmal geht der Ball rein, manchmal nicht. xG-Werte schwanken weniger stark und geben früher Hinweise auf die tatsächliche Stärke einer Mannschaft. Zweitens ermöglichen sie eine bessere Einschätzung von Unter- und Überperformern. Ein Team, das konstant mehr xG produziert als es Tore schießt, wird mit hoher Wahrscheinlichkeit mittelfristig mehr Treffer erzielen – die sogenannte Regression zum Mittelwert. Dieses Wissen nutzen moderne Algorithmen, um kurzfristige Formtiefs von echten Qualitätsproblemen zu unterscheiden.
Allerdings hat auch das xG-Modell seine Grenzen, die oft übersehen werden. Die Berechnung basiert auf historischen Durchschnittswerten: Wie oft wurde aus einer vergleichbaren Situation in der Vergangenheit getroffen? Das funktioniert gut für typische Situationen, stößt aber an seine Grenzen bei Ausnahmespielern. Wenn Erling Haaland aus 20 Metern abzieht, ist die Trefferwahrscheinlichkeit eine andere als beim durchschnittlichen Bundesligastürmer. Manche Modelle versuchen, individuelle Spielerstärken einzubeziehen, aber das erhöht die Komplexität und den Datenbedarf erheblich.
Ein weiterer Kritikpunkt betrifft die Defensive. Während Expected Goals primär auf die Offensivleistung fokussiert, sagt der Wert wenig darüber aus, warum eine Mannschaft die Chancen zugelassen hat, die sie zugelassen hat. War es taktisches Versagen, individuelle Fehler oder kalkuliertes Risiko? Diese Nuancen gehen in der Zahl verloren. Trotzdem bleibt xG das beste verfügbare Werkzeug, um die Qualität einer Spielleistung über das bloße Ergebnis hinaus zu bewerten. Für jeden, der sich mit KI-Prognosen beschäftigt, ist ein grundlegendes Verständnis dieser Metrik unerlässlich.
Wie funktionieren KI-Prognosemodelle im Detail?
Hinter dem Oberbegriff „KI-Prognose" verbergen sich verschiedene technische Ansätze, die sich in ihrer Komplexität und Funktionsweise erheblich unterscheiden. Um die Ergebnisse richtig einordnen zu können, lohnt sich ein genauerer Blick auf die wichtigsten Methoden. Keine Sorge: Du musst kein Informatikstudium absolviert haben, um die Grundprinzipien zu verstehen.
Der klassische Ausgangspunkt vieler Fußballprognosen ist die bereits erwähnte Poisson-Regression. Das Modell geht davon aus, dass die Anzahl der Tore in einem Spiel einer bestimmten statistischen Verteilung folgt. Anhand historischer Daten wird für jedes Team ein Angriffs- und ein Defensivwert geschätzt. Treffen zwei Mannschaften aufeinander, lassen sich aus diesen Werten Wahrscheinlichkeiten für verschiedene Endergebnisse berechnen. Die Stärke dieses Ansatzes liegt in seiner Transparenz: Die Berechnungen sind nachvollziehbar, und die Annahmen sind klar formuliert. Die Schwäche liegt darin, dass das Modell relativ starr ist und komplexe Wechselwirkungen zwischen Faktoren nicht erfassen kann.

Hier setzen Machine-Learning-Algorithmen an. Verfahren wie Random Forest, XGBoost oder Gradient Boosting können deutlich mehr Variablen gleichzeitig berücksichtigen und komplizierte Zusammenhänge erkennen, die einem linearen Modell entgehen würden. Der Random-Forest-Algorithmus beispielsweise baut hunderte von Entscheidungsbäumen, die jeweils auf unterschiedlichen Teilmengen der Daten trainiert werden. Die finale Vorhersage ergibt sich aus dem Zusammenspiel aller Bäume. Dieser Ansatz ist erstaunlich robust gegenüber Ausreißern und kann nichtlineare Beziehungen erfassen – etwa dass die Abwesenheit eines bestimmten Spielers bei Heimspielen stärker ins Gewicht fällt als bei Auswärtsspielen.
Die komplexesten Modelle arbeiten mit neuronalen Netzwerken, inspiriert von der Funktionsweise des menschlichen Gehirns. Diese Systeme bestehen aus vielen Schichten von Recheneinheiten, die miteinander verbunden sind und während des Trainings ihre Verbindungsstärken anpassen. Deep Learning, wie diese Methode oft genannt wird, kann extrem subtile Muster in großen Datenmengen aufspüren. Der Preis dafür ist die sogenannte Black Box: Selbst die Entwickler können oft nicht mehr genau erklären, warum das Modell eine bestimmte Vorhersage trifft. Es funktioniert, aber die Gründe bleiben im Dunkeln.
Eine besondere Rolle spielen Monte-Carlo-Simulationen, die viele der bekannteren Prognoseplattformen einsetzen. Die Idee ist bestechend einfach: Anstatt nur das wahrscheinlichste Ergebnis zu berechnen, wird der komplette Saisonverlauf zehntausende Male virtuell durchgespielt. In jedem Durchlauf entscheiden Zufallsereignisse – basierend auf den berechneten Wahrscheinlichkeiten – über die Ausgänge der einzelnen Spiele. Am Ende zählt man aus, in wie vielen der Simulationen Bayern Meister wurde, wie oft Hoffenheim abgestiegen ist und wie die durchschnittliche Tabelle aussieht. Diese Methode liefert nicht nur einen Tipp, sondern ein vollständiges Bild der Unsicherheit: Wenn Bayern in 95 Prozent der Simulationen Meister wird, ist das etwas anderes, als wenn es nur in 60 Prozent der Fall ist.
Ein oft unterschätzter Aspekt ist das Feature Engineering, also die Kunst, aus Rohdaten aussagekräftige Eingabegrößen für das Modell zu konstruieren. Die Entscheidung, ob man die Tordifferenz der letzten fünf Spiele oder den gewichteten Durchschnitt der letzten zehn Spiele verwendet, kann erhebliche Auswirkungen auf die Prognosequalität haben. Ebenso die Frage, wie man Verletzungen codiert: Zählt nur die Anzahl der Ausfälle, oder gewichtet man nach Spielstärke? Erfahrene Data Scientists verbringen oft mehr Zeit mit diesen Fragen als mit der Auswahl des eigentlichen Algorithmus.
Schließlich ist die Kalibrierung ein entscheidender Qualitätsfaktor. Ein Modell, das behauptet, Bayern gewinne mit 70 Prozent Wahrscheinlichkeit, sollte in Spielen, denen es 70 Prozent zuschreibt, auch tatsächlich etwa 70 Prozent richtig liegen. Viele Modelle neigen zu Overconfidence – sie vergeben zu extreme Wahrscheinlichkeiten, weil sie die inhärente Unsicherheit des Sports unterschätzen. Ein gut kalibriertes Modell ist nicht unbedingt dasjenige, das die meisten Spiele richtig tippt, sondern dasjenige, dessen Wahrscheinlichkeitsangaben der Realität am nächsten kommen.
Zur Verdeutlichung: Ein Modell, das jedem Spiel 50 Prozent Heimsiegwahrscheinlichkeit zuweist, wird etwa die Hälfte aller Heimsiege korrekt „vorhersagen", aber es liefert keinerlei nützliche Information. Ein gutes Modell differenziert zwischen sicheren Favoritensiegen und offenen Partien und liegt mit seinen differenzierten Einschätzungen langfristig richtig. Die Brier-Score ist eine gängige Metrik, um diese Kalibrierungsqualität zu messen, und seriöse Prognose-Anbieter sollten solche Werte transparent kommunizieren.
Die Trefferquote: Wie genau sind KI Bundesliga Prognosen wirklich?
Die alles entscheidende Frage für jeden, der sich mit KI-Prognosen beschäftigt: Funktioniert das Ganze überhaupt? Die Antwort ist unbefriedigend und befriedigend zugleich: Es kommt darauf an, was man unter „funktionieren" versteht. Wer erwartet, dass ein Algorithmus zuverlässig das Ergebnis des nächsten Spieltags vorhersagt, wird enttäuscht. Wer versteht, dass es um Wahrscheinlichkeiten und langfristige Trefferquoten geht, kann durchaus profitieren.
Aktuelle wissenschaftliche Studien zeigen, dass gut konstruierte Machine-Learning-Modelle in ihrer Prognosequalität auf Augenhöhe mit den Einschätzungen großer Buchmacher liegen. Das ist bemerkenswert, denn Buchmacher verfügen über jahrzehntelange Erfahrung und setzen ihrerseits erhebliche Ressourcen in die Quotenfindung ein. Eine Studie aus dem Jahr 2025, die verschiedene ML-Ansätze auf Daten der englischen Premier League anwandte, kam zu dem Schluss, dass die besten Modelle etwa 52 bis 55 Prozent der Spielausgänge korrekt vorhersagen – bei einer Zufallswahrscheinlichkeit von rund 33 Prozent für den 1X2-Markt. Das klingt nach wenig, reicht aber für einen statistischen Vorteil.
Der Vergleich mit menschlichen Experten ist aufschlussreich. In kontrollierten Experimenten schneiden erfahrene Fußballkenner oft ähnlich gut ab wie Algorithmen, manchmal sogar besser. Ihr Vorteil liegt im Kontextwissen: Sie können einschätzen, wie ein neuer Trainer die Mannschaft verändert, welche Bedeutung ein bestimmtes Spiel im Saisonkontext hat oder ob die Meldung einer Spielerverletzung ernst zu nehmen ist. Der Vorteil der KI liegt in der Konsistenz: Sie hat keine schlechten Tage, lässt sich nicht von Emotionen leiten und vergisst keine relevanten Daten. Die optimale Strategie scheint eine Kombination beider Ansätze zu sein.
Ein kritischer Punkt ist die Frage, ob und wie sich mit KI-Prognosen langfristig Gewinne erzielen lassen. Hier muss man realistisch sein: Die Buchmacher sind keine Amateure. Ihre Quoten reflektieren bereits enorme Datenmengen und ausgefeilte Modelle. Der Wettmarkt ist effizient, wenn auch nicht perfekt effizient. Das bedeutet, dass offensichtliche Fehler in den Quoten selten sind und schnell korrigiert werden. Wer glaubt, mit einem einfachen KI-Tool reich zu werden, verkennt die Komplexität des Marktes.
Was KI-Prognosen leisten können, ist die Identifikation von sogenannten Value Bets – Situationen, in denen die Buchmacherquote eine niedrigere Wahrscheinlichkeit impliziert, als das eigene Modell berechnet. Wenn das Modell Bayern eine Siegwahrscheinlichkeit von 75 Prozent zuschreibt, die Quote aber nur eine implizite Wahrscheinlichkeit von 65 Prozent widerspiegelt, könnte ein positiver Erwartungswert vorliegen. Über viele solcher Wetten hinweg kann sich ein Vorteil akkumulieren, selbst wenn einzelne Tipps falsch sind. Das erfordert allerdings Geduld, Disziplin und die Akzeptanz, dass kurzfristige Verluste unvermeidlich sind.
Die ehrlichsten Prognose-Plattformen veröffentlichen ihre historischen Trefferquoten und erlauben so eine Überprüfung ihrer Behauptungen. Hier zeigt sich oft, dass die Realität bescheidener ist als die Werbung. Eine Trefferquote von 55 Prozent ist beachtlich, aber keine Garantie für Gewinne, sobald man die Buchmachermarge berücksichtigt. Die kluge Herangehensweise besteht darin, KI-Prognosen als ein Werkzeug unter vielen zu betrachten, nicht als Orakel mit absoluter Wahrheit.
Kritische Betrachtung: Grenzen und Fallstricke der KI-Prognose
Bei aller Begeisterung für die Möglichkeiten der Datenanalyse dürfen die Grenzen nicht aus dem Blick geraten. Fußball ist und bleibt ein Sport voller Unwägbarkeiten, und kein noch so ausgefeilter Algorithmus kann diese vollständig erfassen. Ein realistisches Verständnis der Grenzen ist nicht nur intellektuell redlich, sondern auch praktisch wichtig für jeden, der KI-Prognosen nutzen möchte.

Die wohl fundamentalste Grenze liegt in der Natur des Spiels selbst. Fußball ist ein Sport mit niedrigen Scores und hoher Varianz. In einer typischen Bundesligapartie fallen zwei bis drei Tore, und oft entscheidet ein einzelner Moment über Sieg oder Niederlage. Ein abgefälschter Schuss, ein Zentimeter Abseits, ein Pfostentreffer in der Nachspielzeit – diese Ereignisse sind für jedes Modell im Wesentlichen zufällig. Das berühmte Finale der Champions League 2005, als Liverpool einen 0:3-Rückstand gegen Mailand aufholte, ist das perfekte Beispiel: Jeder Algorithmus hätte Liverpool zu diesem Zeitpunkt eine einstellige Siegwahrscheinlichkeit gegeben. Und doch gewannen sie.
Ein eng verwandtes Problem ist die Frage, was die Modelle überhaupt erfassen können. Daten beschreiben, was auf dem Platz passiert ist: Laufwege, Pässe, Schüsse. Sie erfassen nicht, was in den Köpfen der Spieler vorgeht. Motivation, Nervosität, Teamchemie, die besondere Bedeutung eines Derbys – all das sind Faktoren, die sich nicht oder nur unzureichend quantifizieren lassen. Ein Modell weiß nicht, dass ein bestimmter Spieler nach einer Scheidung eine schwere Phase durchmacht, oder dass die Mannschaft nach einer internen Krise besonders zusammengeschweißt ist. Menschliche Experten können solche Informationen einbeziehen, wenn sie verfügbar sind.
Dann ist da die Frage der Datenqualität. Das Prinzip „Garbage In, Garbage Out" gilt uneingeschränkt: Wenn die Eingabedaten fehlerhaft oder verzerrt sind, kann das beste Modell nur Unsinn produzieren. In der Bundesliga ist die Datenlage ausgezeichnet, mit präzisem Tracking und umfangreichen Statistiken. Aber schon in der zweiten Liga werden die Daten dünner, und in kleineren Wettbewerben fehlen oft grundlegende Informationen. Modelle, die auf Bundesligadaten trainiert wurden, lassen sich nicht ohne Weiteres auf andere Ligen übertragen.
Das Problem der Overfitting verdient besondere Aufmerksamkeit. Ein Modell kann die Trainingsdaten perfekt erklären und trotzdem bei neuen Daten kläglich versagen. Das passiert, wenn der Algorithmus Muster lernt, die zufällig sind statt echte Zusammenhänge zu reflektieren. Die Technik, um dieses Problem zu adressieren, nennt sich Kreuzvalidierung: Man testet das Modell auf Daten, die es beim Training nicht gesehen hat. Trotzdem bleibt ein Restrisiko, insbesondere bei komplexen Deep-Learning-Modellen mit Millionen von Parametern.
Ein oft übersehener Aspekt ist die reflexive Natur von Prognosen. Wenn genug Leute denselben KI-Tipps folgen, verschieben sich die Buchmacherquoten, und der vermeintliche Vorteil verschwindet. Der Wettmarkt ist ein adaptives System, das auf neue Informationen reagiert. Was gestern ein Value Bet war, muss es morgen nicht mehr sein. Dieser Effekt wird umso stärker, je populärer bestimmte Prognosetools werden. In einem perfekt effizienten Markt gäbe es keine systematischen Vorteile mehr zu holen. Dass der Wettmarkt nicht perfekt effizient ist, gibt Grund zur Hoffnung, aber die Margen sind klein und werden kleiner.
Ein weiteres Problem ist die historische Begrenztheit der Trainingsdaten. Fußball verändert sich: Taktiken entwickeln sich weiter, Regeln werden angepasst, die physischen Anforderungen steigen. Ein Modell, das auf Daten von vor zehn Jahren trainiert wurde, erfasst die heutige Bundesliga nur unvollständig. Die Herausforderung besteht darin, genug historische Daten für robuste Schätzungen zu haben und gleichzeitig veraltete Muster nicht überzubewerten. Diese Balance ist technisch anspruchsvoll und wird von verschiedenen Modellen unterschiedlich gelöst.
Schließlich gibt es ethische Bedenken, die nicht ignoriert werden sollten. Die Leichtigkeit, mit der KI-Prognosen versprechen, Sportwetten zum Kinderspiel zu machen, kann problematisches Spielverhalten fördern. Die Wahrheit ist, dass selbst die besten Modelle keine garantierten Gewinne liefern und dass die Risiken des Glücksspiels real bleiben. Seriöse Anbieter weisen darauf hin; unseriöse versprechen unrealistische Renditen. Die Fähigkeit, zwischen beiden zu unterscheiden, ist vielleicht die wichtigste Kompetenz im Umgang mit KI-Prognosen.
Praktische Anwendung: KI-Prognosen richtig nutzen
Nach all der Theorie stellt sich die Frage: Wie lassen sich KI-Prognosen im Alltag sinnvoll nutzen? Die Antwort hängt davon ab, was du erreichen möchtest. Für manche geht es um Unterhaltung und die Faszination der Zahlen; für andere um die Optimierung ihrer Wettstrategie; für wieder andere um ein tieferes Verständnis des Spiels. In allen Fällen gilt: Blindes Vertrauen ist fehl am Platz, kritische Aneignung ist der Schlüssel.
Der erste Schritt besteht darin, die richtigen Fragen zu stellen. Eine nackte Prognose wie „Bayern gewinnt" ist wenig hilfreich, wenn du nicht weißt, auf welcher Datenbasis sie beruht und wie hoch die Unsicherheit ist. Seriöse Plattformen liefern Wahrscheinlichkeitsverteilungen statt binärer Tipps. Sie erklären zumindest in Grundzügen ihre Methodik und veröffentlichen ihre historischen Trefferquoten. Wenn eine Seite behauptet, 80 Prozent aller Spiele richtig zu tippen, ohne Belege zu liefern, ist Skepsis angebracht.
Für den Einsatz im Wettkontext hat sich das Konzept der Value Bets bewährt. Die Idee ist einfach: Du vergleichst die Wahrscheinlichkeit, die dein Modell (oder ein vertrauenswürdiges Tool) einem Ergebnis zuschreibt, mit der impliziten Wahrscheinlichkeit, die sich aus der Buchmacherquote ergibt. Liegt deine Einschätzung höher als die Quote suggeriert, könnte ein positiver Erwartungswert vorliegen. Das bedeutet nicht, dass du die Wette gewinnst – im Einzelfall kann alles passieren –, aber über viele Wetten hinweg sollte sich ein Vorteil akkumulieren. Dieses Konzept erfordert Disziplin, denn kurzfristige Verluste sind unvermeidlich.
Ein unterschätzter Nutzen von KI-Prognosen liegt abseits des Wettens. Die detaillierten Analysen helfen dabei, das eigene Fußballverständnis zu schärfen. Wer regelmäßig xG-Werte studiert, lernt, Spielleistungen jenseits des bloßen Ergebnisses zu bewerten. Wer Formkurven über mehrere Spieltage verfolgt, entwickelt ein Gespür für Trends, die dem Gelegenheitszuschauer entgehen. Wer sich mit Saisonprognosen beschäftigt, versteht besser, warum bestimmte Mannschaften als Favoriten oder Außenseiter gelten. Diese Art der informierten Auseinandersetzung mit dem Spiel kann unabhängig von finanziellen Interessen bereichernd sein.
Bei der Kombination von KI-Daten mit eigener Expertise empfiehlt sich ein strukturierter Ansatz. Nimm die Prognose als Ausgangspunkt, nicht als Endstation. Frag dich: Welche Faktoren könnte das Modell übersehen haben? Gibt es aktuelle Nachrichten, die in den Daten noch nicht reflektiert sind? Wie relevant ist der direkte Vergleich der letzten Jahre wirklich? Manchmal wirst du zum Schluss kommen, dass die KI recht hat; manchmal wirst du begründet abweichen. In beiden Fällen hast du eine bewusstere Entscheidung getroffen.
Was du unbedingt vermeiden solltest, ist die Jagd nach dem perfekten System. Es gibt kein Modell, das immer richtig liegt, und die Suche danach führt oft in die Irre. Ebenso problematisch ist die Tendenz, nach Verlusten die Strategie radikal zu ändern. Kurzfristige Schwankungen sind normal und sagen wenig über die langfristige Qualität einer Methode aus. Die erfolgreichsten Nutzer von KI-Prognosen zeichnen sich durch Geduld und Konsistenz aus, nicht durch ständiges Experimentieren mit neuen Ansätzen.
Ein letzter praktischer Hinweis betrifft die Dokumentation. Führe Buch über deine Entscheidungen: Welche Prognosen hast du genutzt, wo bist du abgewichen, was war das Ergebnis? Nur so lässt sich langfristig beurteilen, ob deine Strategie funktioniert und wo Verbesserungspotenzial liegt. Diese Disziplin ist mühsam, aber unverzichtbar für jeden, der ernsthaft mit KI-Prognosen arbeiten möchte. Der größte Fehler ist nicht, einen einzelnen Tipp falsch zu liegen, sondern aus den eigenen Erfahrungen nichts zu lernen.
Bekannte KI-Prognosetools im Überblick
Der Markt für KI-basierte Fußballprognosen wächst stetig, und es fällt schwer, den Überblick zu behalten. Ohne einzelne Anbieter zu bewerben, lohnt sich ein Blick auf die verschiedenen Kategorien und Ansätze, die derzeit verfügbar sind. Dabei unterscheiden sich die Tools erheblich in Transparenz, Methodik und Preisgestaltung.
In der Kategorie der Supercomputer-Simulationen finden sich Dienste, die komplette Saisons zehntausende Male durchspielen und daraus Tabellenprognosen ableiten. Diese Systeme werden oft von großen Medienunternehmen oder Datenanbietern betrieben und liefern beeindruckend detaillierte Ergebnisse: nicht nur den voraussichtlichen Meister, sondern auch Wahrscheinlichkeiten für jeden Tabellenplatz, für Auf- und Abstieg, für die Champions-League-Qualifikation. Der Vorteil liegt in der Vollständigkeit; der Nachteil darin, dass die Methodik oft eine Black Box bleibt.
Eine zweite Kategorie bilden Plattformen, die primär auf Expected-Goals-Daten basieren. Sie analysieren jede Partie im Detail, berechnen xG-Werte und leiten daraus Wahrscheinlichkeiten ab. Diese Tools sind oft transparenter in ihrer Methodik und ermöglichen ein tieferes Verständnis der zugrundeliegenden Logik. Für Nutzer, die nicht nur Tipps konsumieren, sondern verstehen wollen, wie sie zustande kommen, ist das ein erheblicher Vorteil.
Dann gibt es die sprachmodellbasierten Ansätze, bei denen Systeme wie ChatGPT oder Claude mit Spieldaten gefüttert werden und auf dieser Basis Prognosen erstellen. Diese Tools sind leicht zugänglich und können natürlichsprachliche Fragen beantworten. Ihre Treffergenauigkeit variiert allerdings stark, und die mangelnde Spezialisierung auf Fußball ist ein struktureller Nachteil gegenüber dedizierten Prognosemodellen.
Bei der Auswahl eines Tools sollten mehrere Kriterien im Vordergrund stehen. Transparenz der Methodik ist essenziell: Erklärt der Anbieter, wie die Prognosen zustande kommen? Historische Performance sollte überprüfbar sein: Gibt es verifizierbare Daten zur bisherigen Trefferquote? Kosten und Geschäftsmodell verdienen Aufmerksamkeit: Finanziert sich die Plattform über Werbung, Affiliate-Links zu Buchmachern oder Abonnements? All das beeinflusst potenzielle Interessenkonflikte. Schließlich spielt die Benutzerfreundlichkeit eine Rolle: Die besten Daten nützen wenig, wenn sie unübersichtlich präsentiert werden.
Kostenlose Angebote sind zahlreich vorhanden, und ihre Qualität ist besser als ihr Ruf. Viele seriöse Plattformen stellen grundlegende Prognosen kostenfrei zur Verfügung und monetarisieren über Premium-Features oder Buchmacher-Partnerschaften. Für den Einstieg reicht das völlig aus. Kostenpflichtige Dienste lohnen sich erst, wenn du genau weißt, was du brauchst und warum die Basisversion nicht ausreicht.
Ausblick: Die Zukunft der KI Bundesliga Prognose
Die Entwicklung der letzten Jahre lässt erahnen, wohin die Reise geht. Die Modelle werden besser, die Daten werden umfangreicher, und die Rechenleistung wächst exponentiell. Was bedeutet das für die Zukunft der KI-gestützten Spielvorhersage?

Ein klarer Trend ist die Integration von Echtzeitdaten. Bereits heute passen manche Systeme ihre Prognosen an, sobald ein Spieler kurzfristig ausfällt oder die Aufstellung bekannt wird. In Zukunft könnte das noch weiter gehen: Modelle, die während des Spiels Live-Daten verarbeiten und ihre Vorhersagen minütlich anpassen. Die technischen Voraussetzungen sind größtenteils gegeben; die Herausforderung liegt in der sinnvollen Nutzung dieser Informationsflut.
Ein anderer Entwicklungsstrang betrifft die Individualisierung der Spieleranalyse. Statt Teams als monolithische Einheiten zu behandeln, könnten zukünftige Modelle jeden Spieler separat modellieren und die Wechselwirkungen zwischen ihnen berücksichtigen. Wie verändert sich das Münchner Spiel, wenn Musiala verletzt ist? Welchen Einfluss hat ein neuer Sechser auf die defensive Stabilität? Solche Fragen ließen sich mit detaillierten Spielermodellen präziser beantworten als heute.
Die größte Unbekannte bleibt, ob KI jemals die qualitativen Aspekte des Fußballs erfassen kann: Motivation, Teamgeist, die besondere Atmosphäre eines Derbys. Optimisten argumentieren, dass sich auch diese Faktoren irgendwann quantifizieren lassen, etwa über Sentiment-Analyse von Spielerinterviews oder physiologische Daten aus dem Training. Skeptiker halten dagegen, dass der Kern dessen, was Fußball ausmacht, per Definition der Quantifizierung entgleitet. Die Wahrheit liegt vermutlich dazwischen. Bestimmte weiche Faktoren werden sich in Zukunft besser messen lassen als heute, aber ein Rest von Unvorhersehbarkeit wird bleiben – und das ist vielleicht auch gut so.
Die regulatorische Dimension verdient ebenfalls Beachtung. Je mächtiger Prognosetools werden, desto mehr stellen sich Fragen nach fairer Nutzung und potenziellem Missbrauch. Sollte jeder Zugang zu denselben Analysen haben? Wie lässt sich verhindern, dass übermächtige Algorithmen den Wettmarkt verzerren? Diese Diskussionen stehen noch am Anfang, werden aber in den kommenden Jahren an Bedeutung gewinnen.
Was sich mit Sicherheit sagen lässt: Die Demokratisierung der Datenanalyse wird weitergehen. Was vor zehn Jahren nur Profis und Buchmachern zugänglich war, ist heute für jeden verfügbar, der sich dafür interessiert. Das verändert die Art, wie wir Fußball schauen und diskutieren. Ob diese Entwicklung den Sport bereichert oder entzaubert, darüber lässt sich streiten. Klar ist, dass sie nicht mehr rückgängig zu machen ist.
Häufig gestellte Fragen
Wie funktioniert eine KI Bundesliga Prognose und welche Daten fließen ein?
Eine KI Bundesliga Prognose basiert auf Algorithmen des maschinellen Lernens, die historische Spieldaten analysieren, um Wahrscheinlichkeiten für zukünftige Spielausgänge zu berechnen. In die Modelle fließen klassische Statistiken wie Tore, Schüsse und Ballbesitz ebenso ein wie fortgeschrittene Metriken, insbesondere Expected Goals. Viele Systeme berücksichtigen zusätzlich externe Faktoren wie Verletzungen, Reisedistanzen, englische Wochen und Marktwerte der Spieler. Die Qualität der Prognose hängt entscheidend von der Datenbasis und der Modellkonstruktion ab. Moderne Ansätze nutzen Verfahren wie Random Forest, XGBoost oder neuronale Netzwerke und simulieren Spielausgänge oft zehntausende Male, um robuste Wahrscheinlichkeitsschätzungen zu erhalten.
Sind KI-gestützte Vorhersagen zuverlässiger als menschliche Experten?
Die Forschung zeigt, dass gut konstruierte KI-Modelle in ihrer Treffergenauigkeit auf Augenhöhe mit professionellen Buchmachern und erfahrenen Experten liegen. Weder Mensch noch Maschine hat einen klaren Gesamtvorteil. Die Stärke der KI liegt in der Konsistenz, der emotionsfreien Analyse und der Fähigkeit, große Datenmengen zu verarbeiten. Menschliche Experten punkten dagegen beim Kontextwissen: Sie können aktuelle Nachrichten, Mannschaftsdynamiken und schwer quantifizierbare Faktoren einbeziehen. Die vielversprechendste Strategie kombiniert beide Ansätze und nutzt KI-Daten als Fundament, das mit menschlichem Urteilsvermögen ergänzt wird. Absolute Zuverlässigkeit bietet keiner der Ansätze, da Fußball inhärent unvorhersehbare Elemente enthält.
Was bedeutet Expected Goals und wie beeinflusst es die Prognosequalität?
Expected Goals, kurz xG, ist eine statistische Kennzahl, die die Qualität von Torchancen misst. Jeder Torschuss erhält einen Wert zwischen 0 und 1, der angibt, wie wahrscheinlich aus einer vergleichbaren Situation historisch gesehen ein Tor gefallen ist. Ein Schuss aus fünf Metern zentral vor dem Tor hat einen höheren xG-Wert als ein Fernschuss aus spitzem Winkel. Für KI-Prognosen ist xG aus zwei Gründen wertvoll: Erstens liefert es ein stabileres Signal als reine Torstatistiken, da es weniger von Zufallsschwankungen beeinflusst wird. Zweitens ermöglicht es die Identifikation von Über- und Unterperformern, also Teams, die mehr oder weniger Tore schießen als aufgrund ihrer Chancenqualität zu erwarten wäre. Diese Erkenntnis hilft bei der Prognose zukünftiger Ergebnisse.